The image sequence above shows AI generation by a so-called diffusion model, specifically runwayml/stable-diffusion-v1-5 (obtained from Hugging Face). the Google Colab notebook that generated it is here. The final image – usually the only one you see – is on the far right. On the far left is an image that is near the start of the image-generation process. Image generation starts with just noise, along with the prompt to specify what you want the image to be: “a cute British short hair kitten, looking directly at you”. Then an iterative procedure is applied, in this case 48 times, to somehow subtract the noise to leave the kitten.
Author Archives: Richard Sear
Computational physicist at the University of Surrey. My research interests are in COVID-19 transmission, especially masks, soft matter & biological physics
“Physics” as an LLM understands it

Large Language Models like OpenAI’s ChatGPT, Google’s Gemini, Anthropic’s Claude etc work with words but under their bonnets it is all maths. In particular the meaning of a word is encoded in a vector: a line of numbers, which allows the LLM to do vector maths on it to produce more words: its answer to your question.
How dangerous do masks get?
Masks exist to filter out harmful viruses and bacteria from the air the wearer is breathing. This protects the wearer, and if the mask wearer is infected, it protects others in the same room. Masks are air filters worn on the face and air filters are typically meshes of tiny fibres – illustrated in the rather shonky AI image above. They work by the virus-containing droplets in the air sticking to the fibres inside the filter, and so not going through the mask.
But then what happens to the virus-containing droplets stuck to fibres inside the filter material? There is understandable concern that the mask could be contaminated by these droplets, and that perhaps later infectious virus could be dislodged from the mask and go on to infect someone.
Cool evaporating droplets
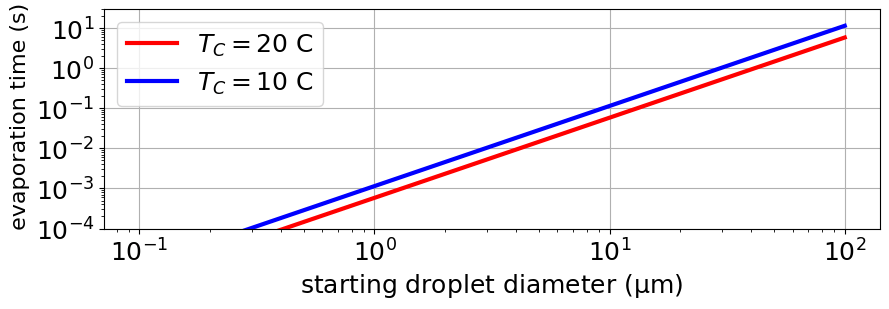
The evaporation of water droplets is a lot more complex than you’d think or hope. One reason is that small water droplets, at least in not very humid air, evaporate so fast that the evaporation cools them. This is just like when you blow on hot coffee to cool it, you increase the evaporation rate and this cools the coffee. Evaporation takes energy, called latent heat levap, which for water is large. At room temperature the latent heat is a bit less than 10−19 J per water molecule that evaporates. Calculations by Hardy et al. find that it can cool an evaporating water droplet by more than 10 C.
Infectious disease superspreaders on ships
At the moment two ships are in the news for infectious disease outbreaks, the MV Hondius for an outbreak of the Andes strain of hantavirus (ANDV) and the Ambition for a norovirus outbreak. This outbreak on the Handius has resulted in three deaths to date. These are just two of a long line of plague ships, including the Diamond Princess during the early stages of the COVID pandemic. Viewed from one way, this is perhaps unsurprising: large cruise ships squeeze several thousand passengers and crew into a confined space that looks a perfect place to transmit disease from one person to another. But I am bit surprised both that the companies that run these ships don’t seem to be doing anything to stop these regular bursts of bad PR, and that potential passengers are not put off by the risk of boarding a potential plague ship.
Predicting next year’s CO2 levels with simple machine learning
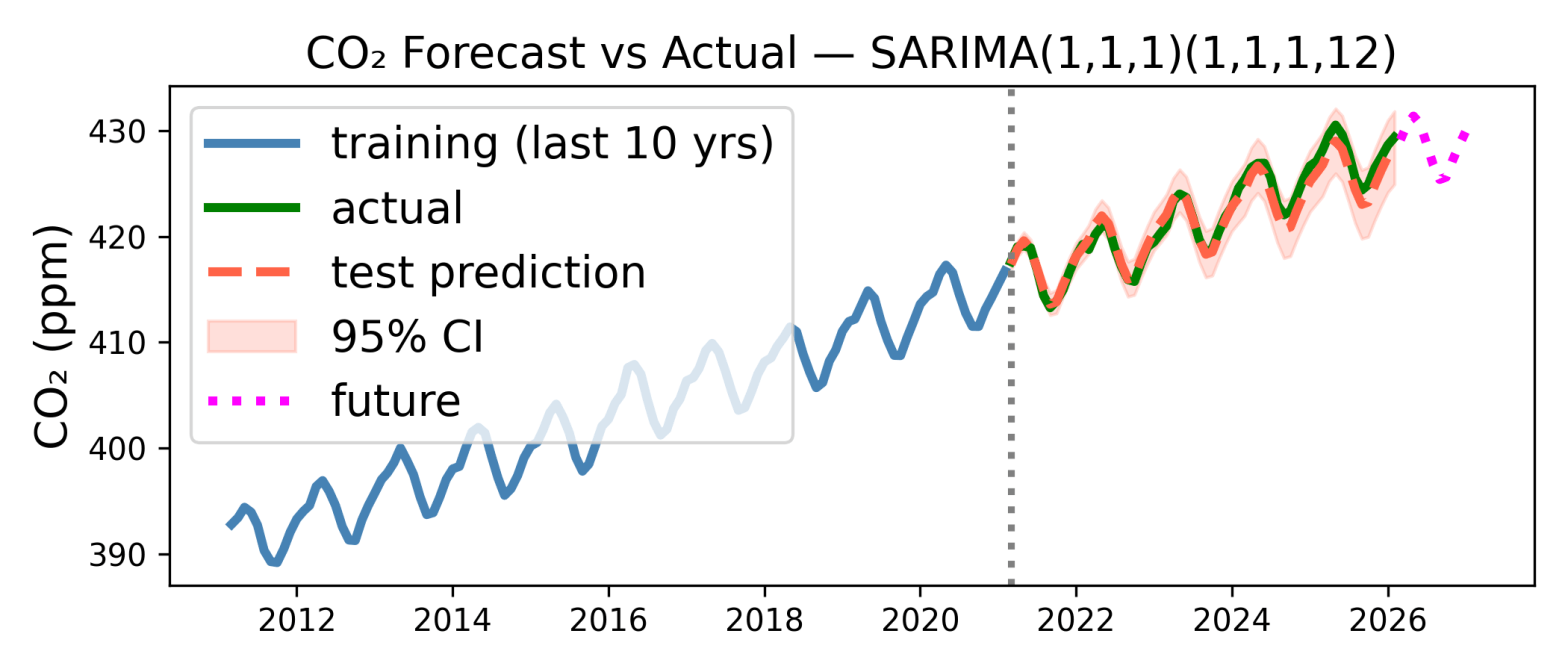
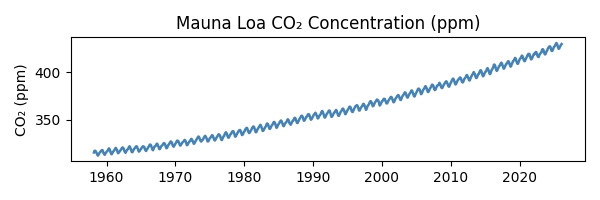
Due to us burning oil, coal, gas etc etc, the amount of CO2 in Earth’s atmosphere is increasing, and has been for well over a century. This is now well documented. Some of the first measurements were made by Charles David Keeling on the Muana Loa volcano*. He started in March 1958, and the measuring continues to this day. Katherine Bourzac has written a fascinating article about the history of these measurements, which with a couple of interruptions have continued to this day, almost 70 years of data. The data** is here:
Hunting by electric fields, and with the Ampullae of Lorenzini

This beautiful image is of the small-spotted catshark, and is by Hans Hillewaert (Wikimedia). They are carnivores and hunt on the seabed, where I think vision is poor. So they have evolved to hunt, in part, by sensing the electric fields due to their prey. This was shown over 50 years ago, with some beautiful work by AJ Kalmijn. There is a lovely Scientific American article on this, by RD Fields, in 2007.
The difference between insanity and genius is measured only by success and failure
The title is a quote by the manga artist Masashi Kishimoto. It is one of many quotes linking insanity and genius, one of them dating all the way back to Aristotle. But now, finally, we can quantify how similar insanity and madness, it is: 0.5810. This may not look that high but insanity is closer to madness than sanity, sanity and madness only have a similarity of 0.4114.
Apps for understanding better the air we breathe
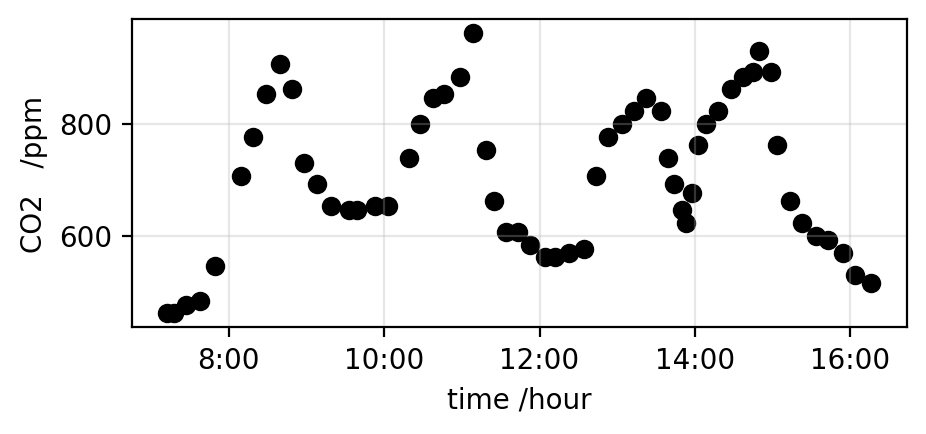
I have been suckered* into running a schools event next week, so spent most of the day writing an app to allow school kids to plot the CO2 concentration of indoor air, and do some very basic analysis. The app is now running, both on Streamlit Community Cloud and Railway*. It takes csv files that have some fraction of a day’s data on CO2 concentration in the air, and plots the data. A plot from the app is shown above. The data on CO2 levels is from a Canadian school, I thought some data on a school might be good to interest the school children.
Rattlesnakes and detecting warmth a thousandth of a degree at a time

This* is the head of a western diamond rattlesnake, a species of pit viper that is common in the USA and Mexico. Pit vipers are a family of species of snakes that called pit vipers because they have a specialised sensor organ – a pit – to detect thermal radiation (ak infrared or IR radiation). This in addition of course to their eyes which detect visible radiation. If you look carefully you can see a pit in the picture above. From left to right it lies about halfway across between the eye and the nostril, and it is close to the bottom of the head. It is hard to see because it is a pit so you really just see the shadow.

{kind=link}